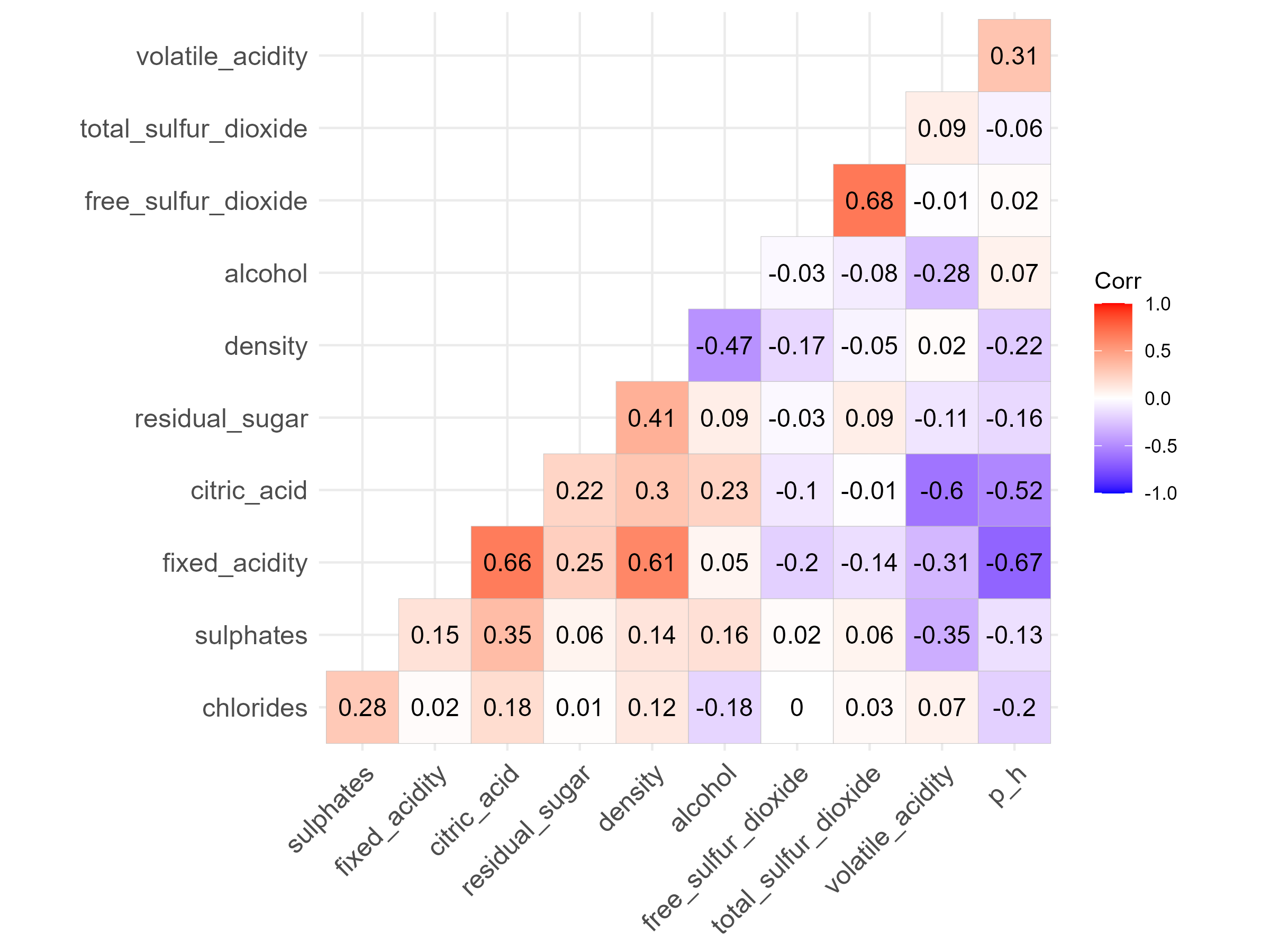
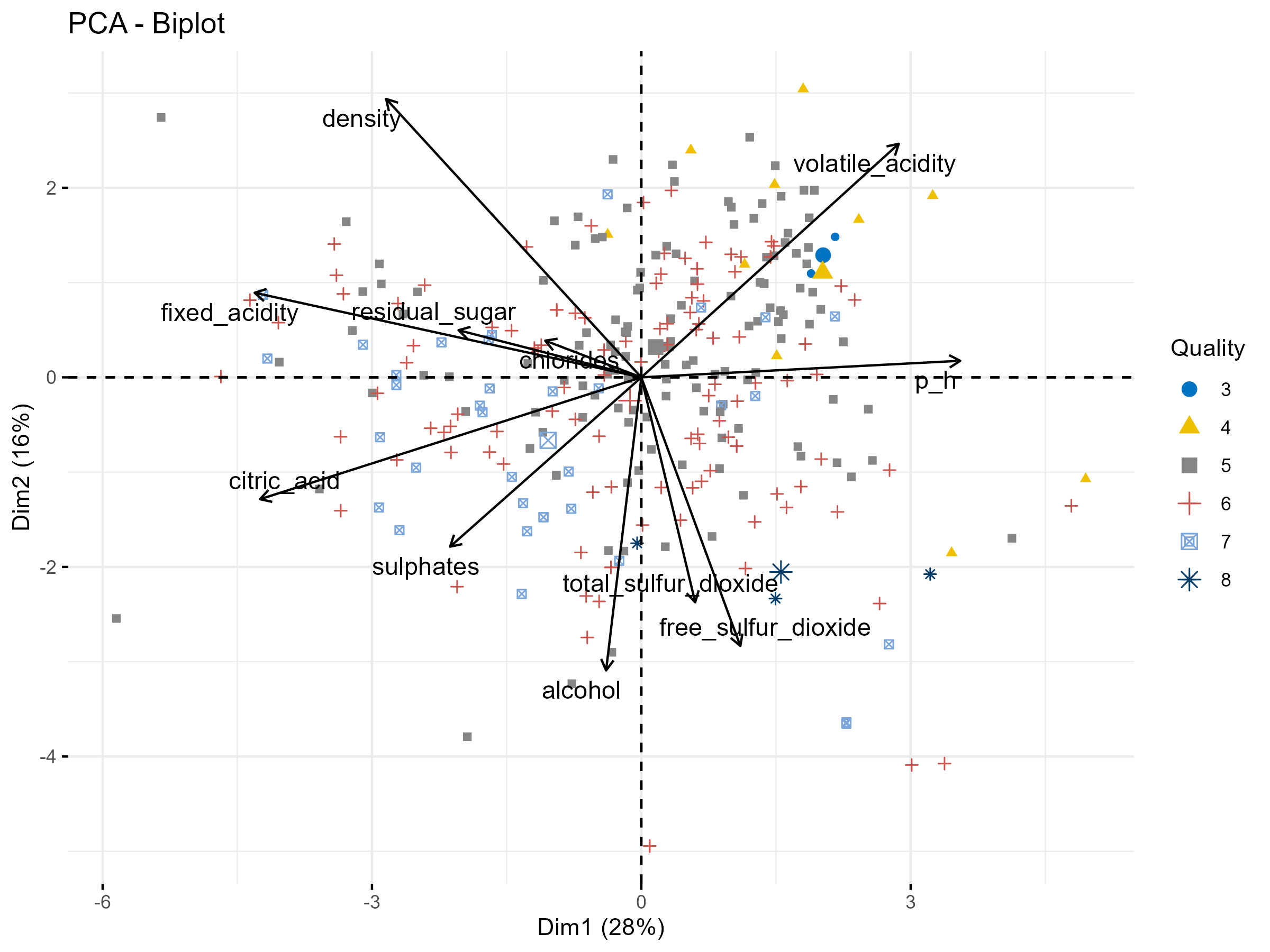
The dataset used in this analysis is from Cortez et al. (2009), which models wine preferences based on physicochemical properties. You can read the data directly from the ecodata R package on Github:
library(tidyverse)# Define the raw URL for the .rda fileurl <-"https://raw.githubusercontent.com/TheoreticalEcology/ecodata/master/data/wine.rda"# Load the .rda file directly from the URLload(url(url))# Convert the data to a tibblewine <-tibble(wine)# Checkout the datawine
P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.